RDMA 学习
概述
RDMA 是 Remote Direct Memory Access 的缩写,意为”远程直接内存访问”,它的基本原理是绕过 CPU 和 操作系统,让通信两端的网卡直接访问用户态内存,完成数据传输。
这种做法省去了上下文切换、内存拷贝、协议处理等开销,在数据传输时能达到较高的带宽和延迟指标:
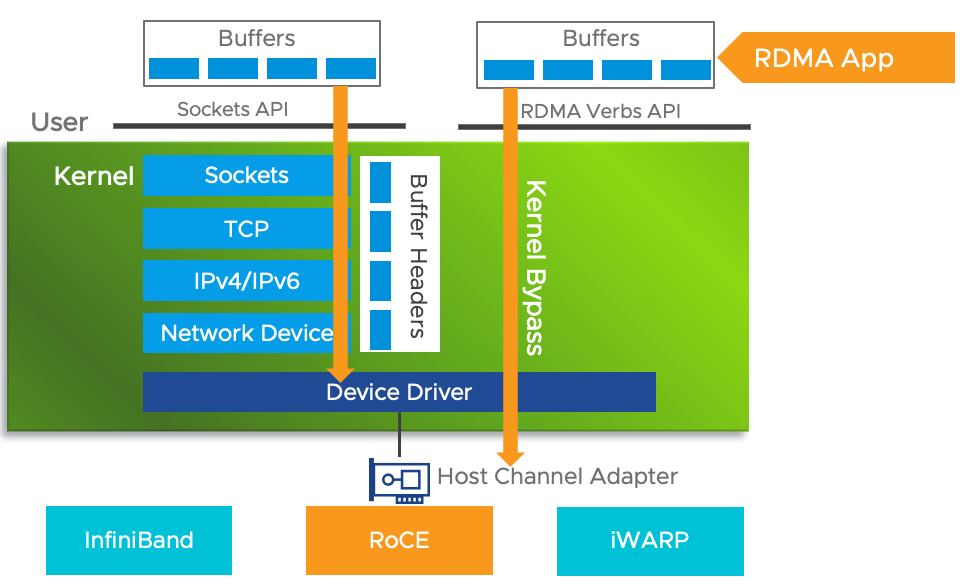
RDMA 技术有几种不同的协议栈实现,但在应用层提供了统一的接口,称为 Verbs API:
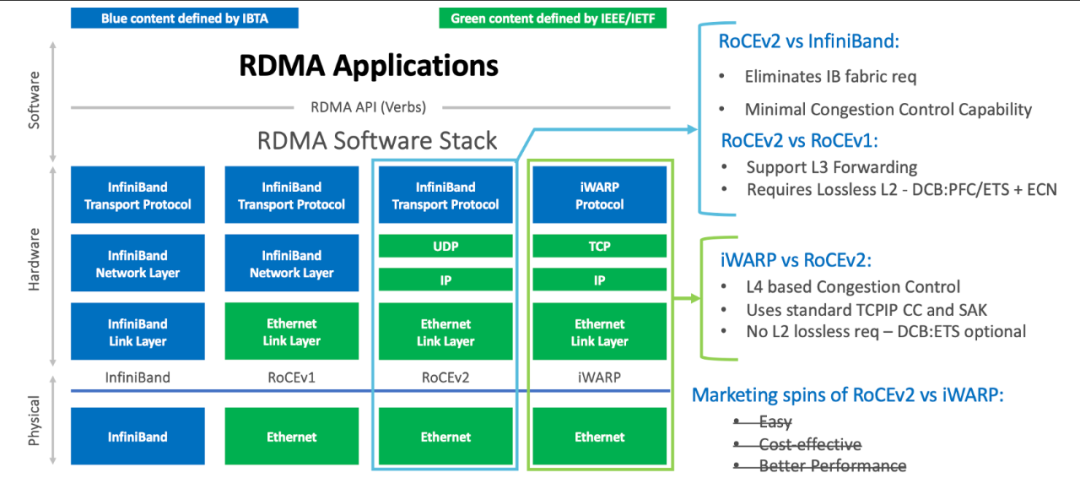
InfiniBand 协议栈需要添置专门的网络设备,无法兼容现有以太网,除了需要支持 IB 的网卡,还需要配套的交换设备。RoCE 协议栈可以看作是“低成本解决方案”,目的是在以太网中运行 RDMA。早期的 RoCE 仅支持在二层以太网上实现 RDMA 传输,换句话说报文没法被路由器路由,使用场景受限。随后的 RoCEv2 把报文封装在了 UDP/IP 报文内,可以跨越子网路由,解除了诸多限制,逐渐流行起来。
值得注意的是上图左侧标明的 “Hardware”,就是说 RDMA 协议栈需要专门的网卡实现,一般网卡是不行的。
下图是 RoCE 和 RoCEv2 的报文结构:

RoCEv2 可以工作在 lossless 和 lossy 网络下:
- Lossless,也就是无损以太网,要求网络中没有差错、丢包、乱序。实现 lossless 需要支持该功能的网卡、交换机,并进行相应的网络配置。涉及的技术包括:
- PFC: Priority Flow Control, 基于优先级的流量控制,让 RDMA 流量具有更高的优先级。
- DCB: Data Center Bridging, 增强的以太网协议,支持无损传输。
- ECN: Explicit Congestion Notification, 显式拥塞通知,交换机发生拥塞会显式通知发送方,发送方可以降低速率。
- Lossy, 也就是有损网络,自 CX5 系列网卡开始支持 RoCE 的增强功能,使得组网规模不大的情况下,也能在 lossy 网络中运行。
Verbs API
跟 Socket API 相比,Verbs API 有些复杂,首先需要理解队列模型:
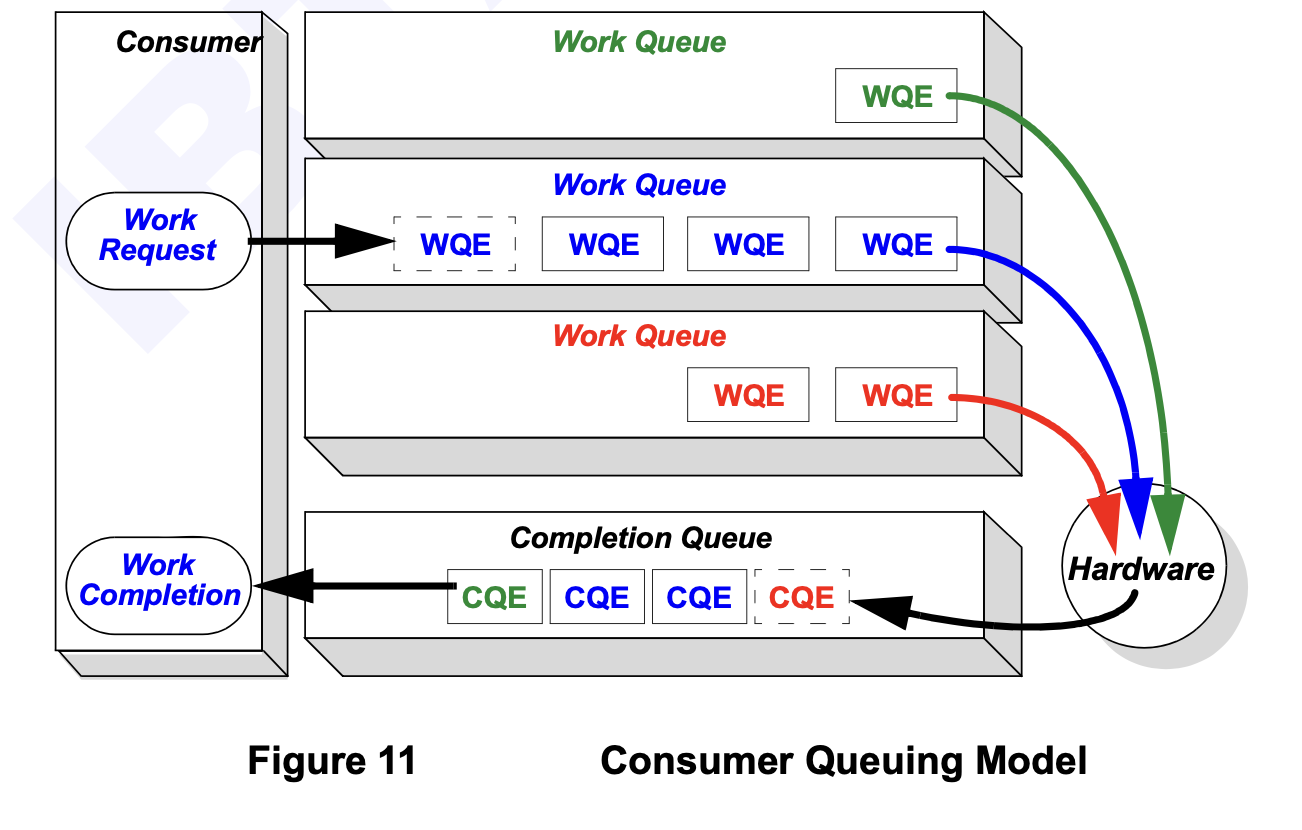
通过 Verbs API 进行数据传输时,需要向 Work Queue 里投递 Work Request, 网卡(HCA)从队列里取出 WQE 执行相应操作,结束后会投递一个 CQE 到 Completion Queue 里,应用层可以从这个队列中取出 Work Completion 得知处理结果。
以下代码片段展示了这一过程:
int main {
// QP 建连、注册 MR 等过程,省略。。。
// 要发送的内存块信息
ibv_sge sg = {
.addr = local_mr.addr,
.length = local_mr.length,
.lkey = local_mr.lkey,
};
// 构造 Work Request, 内容为使用 WRITE 操作,将内存块写入目标地址
ibv_send_wr write_wr{
.wr_id = wr_id,
.sg_list = &sg, // 要发送的内存块
.num_sge = 1,
.opcode = IBV_WR_RDMA_WRITE, // 操作方式
.send_flags = IBV_SEND_SIGNALED,
.wr = {
.rdma = {
.remote_addr = remote_addr, // 远端内存地址信息
.rkey = remote_key,
},
},
};
// 将 Work Request 投递到 Send Queue
ibv_send_wr* bad_send_wr = nullptr;
if (ibv_post_send(&_qp, &write_wr, &bad_send_wr) != 0) {
printf("Failed to post write wr, errno: %d(%s)\n", errno, strerror(errno));
return false;
}
sleep(1000);
// 从 Completion Queue 里取出 Work Completion
ibv_wc wc_list[1] = {}
if (ibv_poll_cq(&_cq, 1, wc_list) < 0) {
printf("Failed to poll work completions from cq, errno: %d(%s)\n", errno, strerror(errno));
return std::nullopt;
}
// 检查是否执行成功
if (wc.status != IBV_WC_SUCCESS) {
printf("Failed WC status %d(%s) for wr_id %lu\n", wc.status, ibv_wc_status_str(wc.status), wc.wr_id);
return 1;
}
}
理解了队列模型之后,剩余的概念就比较好解释了:
| 概念 | 缩写 | 解释 |
|---|---|---|
| Send Queue | SQ | 发送队列,顾名思义用于存放发送任务。 在 API 中使用 ibv_post_send() 方法向该队列投递任务,对应结构体 ibv_send_wr
|
| Receive Queue | RQ | 接收队列,用于存放接收任务。 适用于 SEND&RECV 操作,在这种操作模式下,不仅发送方需要向 SQ 中投递发送任务,接收方也需要在 RQ 中投递接收任务,这样才能收到数据。 在 API 中使用 ibv_recv_wr 投递接收任务,对应结构体 ibv_recv_wr
|
| Queue Pair | QP | 也就是一对 SQ 和 RQ。 QP 和 QP 之间可以绑定起来建立连接关系。 QP 有一个编号来标识,称为 Queue Pair Number, 简称 QPN。 |
| Shared Receive Queue | SRQ | 多个 QP 共享一个 Receive Queue, 从上面讨论可以看出 Receive Queue 的使用频率比较低,大多数情况下是在使用 Send Queue, 因此可以通过共享来节省资源。 |
| Memory Region | MR | 用户态申请的内存不能直接被网卡访问,需要先注册到 Memory Region 上。 在 API 中使用 ibv_reg_mr() 注册 MR, 使用 ibv_dereg_mr() 取消注册,对应结构体 ibv_mr
|
| Memory Window | MW | 相当于时 MR 上某个区域的视图,可以针对这个视图做权限修改,相比于重新注册 MR 来说速度很快。 |
| Protection Domain | PD | 用于保护各类资源,包括 QP, MR 等,相当于对这些资源进行分组,不同组的资源彼此隔离。 在 API 中使用 ibv_create_qp() 创建 PD, 使用 ibv_dealloc_pd() 释放 PD, 对应结构体 ibv_pd
|
| Completion Queue | CQ | 完成队列,硬件每处理完一个 WQE,就会投递一个 CQE 到 CQ 里面。应用可以从中获取出 Work Completion,得知处理结果。 注意一个 CQ 可以为多个 QP 提供服务。 在 API 中使用 ibv_poll_cq() 获取 WC, 对应结构体 ibv_wc
|
| Completion Event Channel | 能够使用事件驱动的方式来获取 WC, 而不是通过 poll 模式获取。可以跟若干 CQ 关联起来,每当 CQ 上有了 WC,就可以从 Channnel 中收到事件通知。 在 API 中使用 ibv_create_comp_channel() 创建 channel,使用 ibv_create_cq() 创建 CQ 时传入 channel 即可进行绑定,使用 ibv_req_notify_cq() 要求 CQ 通过 channel 进行事件通知,使用 ibv_get_cq_event() 从 Channel 中阻塞式地获取 CQE, 使用 ibv_ack_cq_events() 确认 CQE。Channel 中有个 fd, 可以跟 epoll 结合使用,这篇文章 描述了具体做法。相比 Poll 模式,这种方式可以节省 CPU 占用,但性能上有一定损失。事件模式 和 Poll 模式可以结合使用,在收到事件之后的一段时间内轮询调用 ibv_poll_cq() 主动获取 WC。 |
RDMA 通信过程可以分为以下几个步骤:
- 创建资源,包括 PD, QP, CQ, CompChannel 等。
- 建立连接
- 注册内存到 MR,这一步是比较耗时的,通常需要对注册好的内存池化管理。
- 数据传输
服务类型
基于 QP 的服务类型通过 “可靠性” 和 “连接” 两个维度划分为四种:
| 可靠(Reliable) | 不可靠(Unreliable) | |
|---|---|---|
| 连接 | RC(Reliable Connection) | UC(Unreliable Connection) |
| 数据报 | RD(Reliable Datagram) | UD(Unreliable Datagram) |
可以看到 RC 类似于 TCP, 通信之前要先建立连接;UD 类似于 TCP,每次发送都需要传入地址信息。
RC 建连
在 TCP 中,建立连接需要 IP 和 Port 两个信息,在 RDMA 中建立 RC 连接需要哪些信息呢?
虽然 RoCEv2 是基于 UDP 的,但它遵循的是 IB 协议,因此从 API 层面并不能看到 UDP 的 IP 和 Port 信息。以下是 RDMA 中地址信息相关的概念:
| 概念 | 缩写 | 解释 |
|---|---|---|
| Global Identifier | GID | 类似于 IP 地址在 TCP/IP 网络中的作用。是一个 128 位的地址,由 64 位的子网前缀和 64 位的接口标识符组成。用于跨越子网的通信。 RoCE 中的 GID 通常由 IPv6 派生而来。 |
| Local Identifier | LID | 类似于 MAC 地址。是一个 16 位的局部标识符,用于标识 InfiniBand 子网中的某个设备。用于子网内的通信。 RoCE 中不需要,它基于 MAC 地址进行子网内部通信。 |
| Port Number | RDMA设备(如 HCA, Host Channel Adapter 也就是网卡)上通常有多个物理端口,每个端口连接到一个独立的网络。这个物理端口以 Port Number 序号进行标识,通常从 1 开始编号。 每个端口都有独立的地址信息,包括 GID, LID 等,因此先要指定 Port Number 才能找到 GID |
|
| GID Index | 每个 Port Number 对应的物理端口上,可以有多个 GID,这些 GID 组成了一个 GID 表,GID Index 就是表中的索引。 这个 GID 表通常用于支持不同类型的地址,比如基于 LID 的 GID、IPv6 地址。 对于 RoCE 来说, Index 为 0 的 GID 由 MAC 地址生成,Index 为 1 的 GID 由 IPv4 地址生成,Index 为 2 的 GID 由 IPv6 地址生成。 |
|
| Queue Pair Number | QPN | 即 QP 的编号 |
| Packet Sequence Number | PSN | 类似于 TCP 握手时交换的 seq 序号,在 RC 建连时需要手动指定。 |
| Address Handle | AH | 封装了地址信息,用于 UD 服务类型,每次发送都需要填入目标地址,AH 提供了目标地址信息的封装,免得每次重新创建。 |
从上面内容来看,建立 RC 连接时至少需要收集 GID, QPN, PSN 这三项信息。以下代码展示了如何获得这些信息:
int main()
{
uint8_t kPortNum = 1; // 选择默认物理端口
int kGidIndex = 2; // 选择 IPv6 GID
// 打开设备
ibv_context* context = ibv_open_device(device);
// 创建 QP, 省略 PD 等细节
ibv_qp* qp = ibv_create_qp(&pd, &qp_init_attr);
// 查询 GID
ibv_gid gid;
if (ibv_query_gid(context, kPortNum, kGidIndex, &gid) != 0) {
printf("Failed to query gid, port_num: %d, gid_index: %d, errno: %d(%s)\n", port_num, gid_index, errno,
strerror(errno));
return std::nullopt;
}
// 查询 QPN
uint32_t qpn = qp.qp_num;
// 生成 PSN
int psn = static_cast<int>(lrand48() & 0xffffff);
// 通过带外方式,通信双方交换 GID, QPN, PSN 信息
// 随后进行 RC 建连
}
这些信息的交换是带外的,RDMA CM(Communication Manager) 是一个专门用来做连接管理的库。也可以使用 TCP 连接等方式来交换信息。
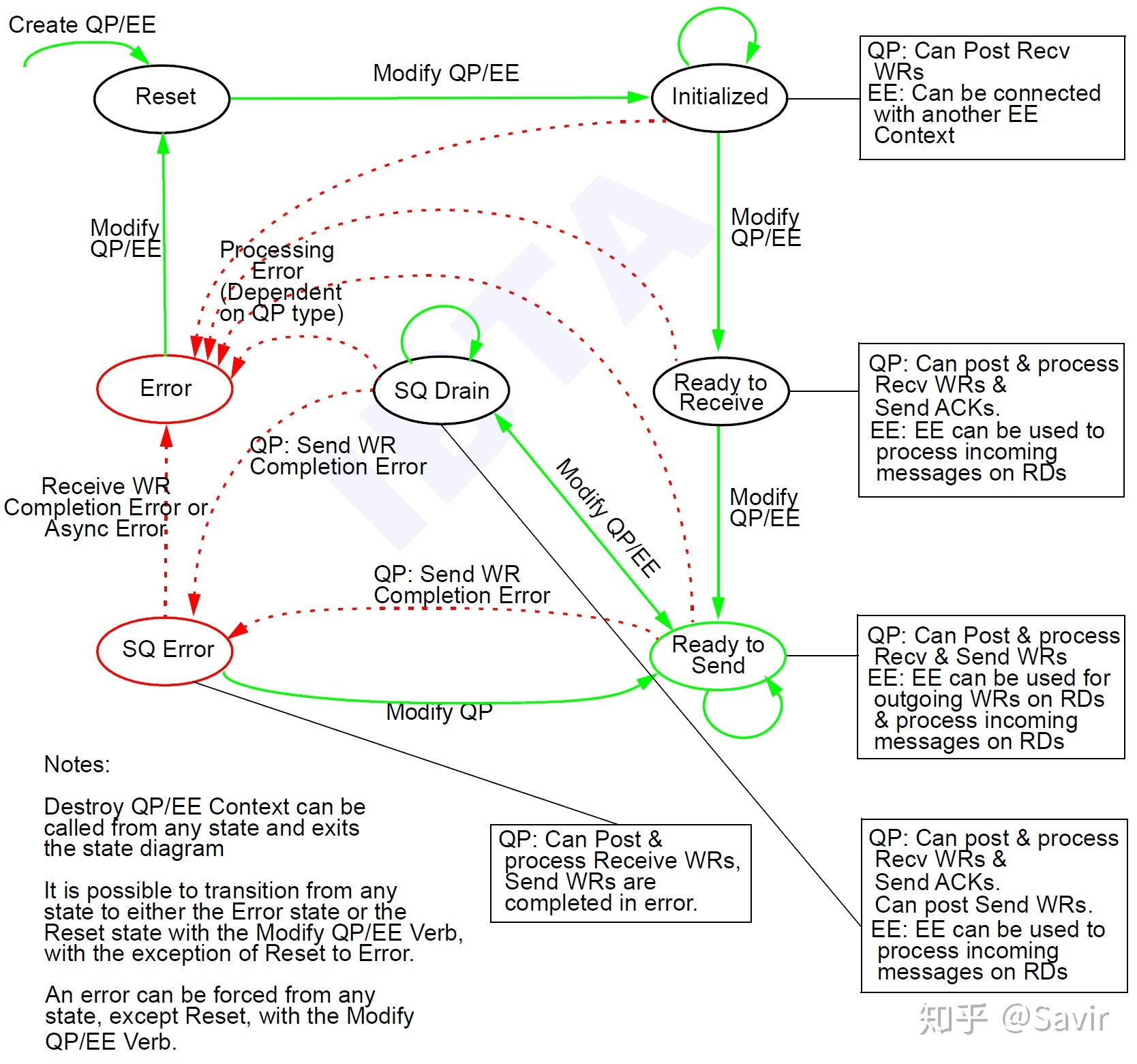
拿到这些信息之后,需要调用 ibv_modify_qp() 方法,建立 RC 连接。建连的过程稍微有些复杂,需要执行三次 modify qp 操作,逐步切换状态: Reset -> Initialized -> Read to Receive -> Ready to Send
操作类型
RDMA 提供了几种不同的操作类型,用于不同场景:
Send&Recv
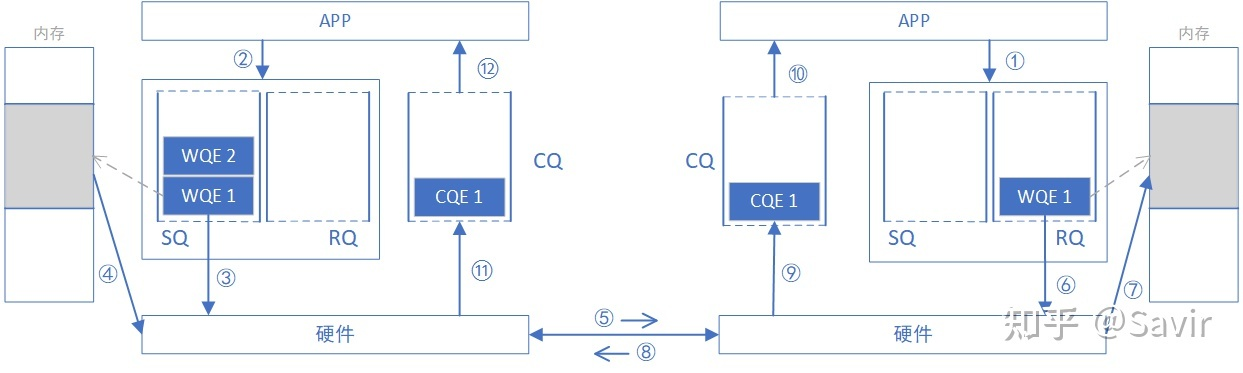
如下图,这种方式需要通信两端都都参与,发送方投递 SEND 任务,接收方投递 RECV 任务:
- 这种方式适合于发送一些控制消息,不太适合大块数据的传输。
- 它要求接收方提前投递 RECV 任务到接收队列里面,并且接收方需要准备一块内存来接收数据。
- 在这种方式下,接收方能够通过 CQ 判断是否有新数据到来。
Write
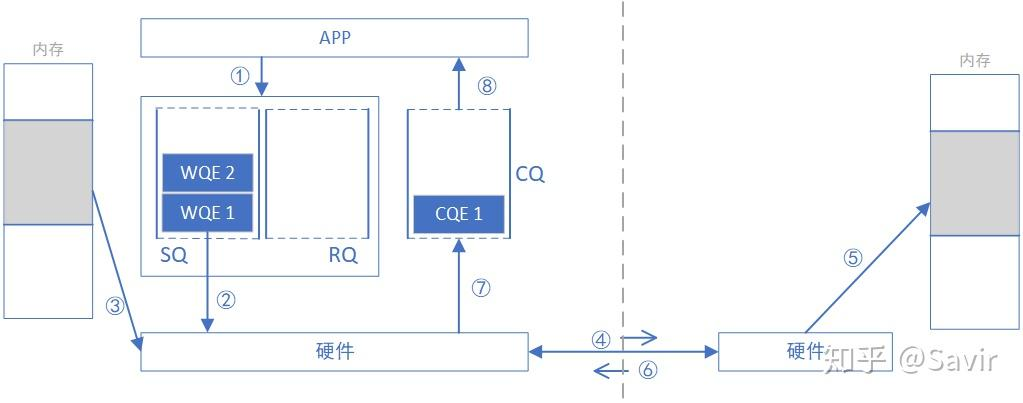
如下图,这种方式是单端操作,接收方需要事先准备一块内存,并且把内存信息通过某种方式告知给发送方,发送方将自己数据写入到接收方的内存中,写入的过程不需要接收方参与。
- 接收方可以通过 Send&Recv 的方式将自己的内存信息告诉发送方。
- 接收方默认是不知道数据已经收到的,发送方可以在发送时指定 IBV_WR_RDMA_WRITE_WITH_IMM, 这样接收方会在 RQ 里额外收到一个消息。当然发送方也可以在 WRITE 完成之后再通过 Send&Recv 通知一下接收方。
Read
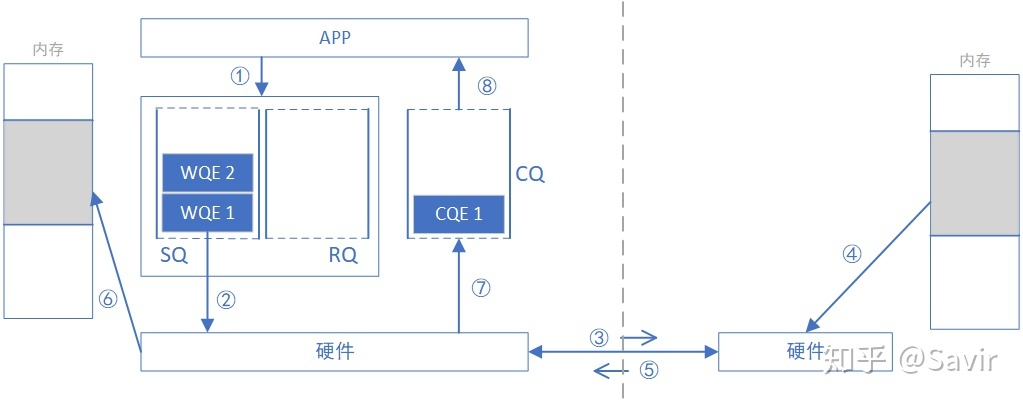
Read 操作是跟 Write 相反的过程,是从远端拷贝一份数据到本端上。同样远端需要事先通过某种方式把内存信息告知过来。
- 同样的,远端机器并不知道自己的数据已经被读取完成了,需要本端通过 Send&Recv 等方式通知远端。
Memory Region
调用 ibv_reg_mr() 即可将一块用户态内存注册到 MR 中:
ibv_mr* allocMemAndRegMr(size_t mem_size) {
// 申请内存,并且要求进行页对齐
// 对齐并不是强制的,但是 ChatGPT 说页对齐之后性能会好点,没找到出处
// rdma-core 的 pingpong 示例程序里也是进行了页对齐的
size_t alignment = _SC_PAGESIZE;
void* mem_addr = memalign(alignment, mem_size);
// 指定 MR 的访问权限
int access_flags_int = IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_WRITE;
// 注册到 MR 上
ibv_mr* mr = ibv_reg_mr(&_pd, mem_addr, mem_size, access_flags_int);
return mr;
}
注册后返回的 ibv_mr 是个结构体,其中包含了 lkey, rkey 两把钥匙。在执行不同任务时,需要按照需求带上相应的 key。具体可以参考 RDMAmojo.